SRD Protocol 알아보기
Elastic Network Adapter (ENA) Express를 지탱하는 SRD 프로토콜
Get read with me~ 🧐
🚨 이번 포스팅은 SRD에 대하여 잘못 설명하고 있는 내용이 매우 많을 수 있음을 알립니다. 해당 포스팅은 SRD와 관련된 논문을 이해하기 위해 공부한 과정을 담은 산출물로 봐주세요!
Intro
작년 11월 28일 What’s New with AWS?에는 ENA Express라는 기술을 사용 가능해졌음을 알렸습니다.
️🔗 Introducing Elastic Network Adapter (ENA) Express for Amazon EC2 instances
ENA Express를 사용하면, single flow 대역폭을 5 Gbps에서 최대 25 Gbps까지 늘릴 수 있다고 합니다. 해당 기능을 활성화시키는 방법은 AWS News Blog에 잘 소개되어 있습니다.
️🔗️ New – ENA Express: Improved Network Latency and Per-Flow Performance on EC2
어떻게 ENA Express는 비약적인 성능 향상을 일으킬 수 있었을까요? 이번 포스팅에서는 아마존의 독자 프로세서(Graviton)를 만든 Annapurna Labs가 IEEE에 개재한 paper를 통해 ENA Express 기술을 지탱하는 SRD 프로토콜에 대하여 알아보겠습니다.
️🔗️ A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC
📄 모양은 Paper에 실린 내용을 DeepL과 papago 번역을 바탕으로 요약한 내용이며,
🗣️ 모양에서 배경지식과 부연 설명 등을 언급합니다.
Abstract
📄 안나푸르나 연구소는 현재 상용되는 multitenant 데이터 센터 네트워크는 부하의 불균형(load imbalance) 및 일관되지 않은 지연 시간 등의 제약 사항을 극복할 수 있도록 새로운 네트워크 전송 프로토콜인 Scalable Reliable Datagram (SRD)를 만들었다고 합니다. SRD는 패킷 순서를 유지하는 대신, overload된 경로를 피하며 가능한 많은 네트워크 경로를 통해 패킷을 전송합니다. SRD는 지터를 최소화하고 네트워크 혼잡 변동에 가장 빠르게 대응하기 위해 Nitro 네트워킹 카드에 구현되었습니다. SRD는 AWS EFA 커널 바이패스 인터페이스를 통해 HPC(고성능 컴퓨팅)/ML 프레임워크에서 사용됩니다.
- Multitenant : 서버 리소스가 서로 다른 사용자 간에 분할되는 공유 호스팅
- Jitter : 네트워크에서 종단 간 지연 시간에 따른 변동성에서 측정된 latency의 변화
🗣️ 초록에 SRD의 탄생 배경이 잘 요약되어 있지만, “EFA 커널 바이패스 인터페이스를 통해~”라는 부분에 대하여 부연 설명을 몇 자 적어보겠습니다.
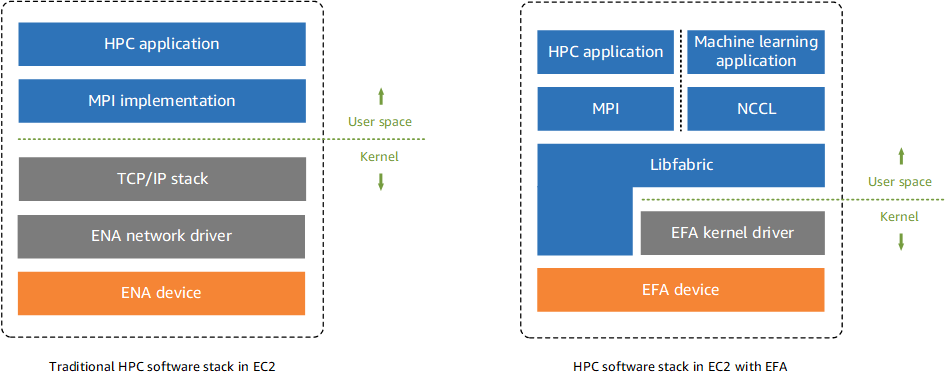
설명하기 앞서, Enhanced Networking에 대하여 언급하겠습니다. 향상된 네트워킹은 더 높은 대역폭, 더 높은 PPS(초당 패킷) 성능 및 지속적으로 더 낮은 지연시간을 제공합니다. 이를 지원하기 위해 Elastic Network Adapter(ENA)와 Intel 82599 Virtual Function (VF) interface 메커니즘을 사용하는 방법이 있습니다. 사진의 왼쪽 부분은 언급한 2가지 방법 중 ENA software stack입니다. 애플리케이션은 MPI(Message Passing Interface)를 사용하여 시스템의 network transport와 정보를 주고받습니다(interface). 이 방법은 운영체제의 TCP/IP 스택과 ENA 드라이버를 사용해 네트워크 통신을 가능하게 합니다.
반면 오른쪽의 EFA는 Libfabric API를 통해 인터페이스 하므로 운영체제 커널을 우회하고 EFA 장치와 직접 통신해 오버헤드가 줄어들게 됩니다. ENA와 EFA는 향상된 네트워킹 성능을 제공함으로써, 고성능 컴퓨팅 작업과 기계학습 등에 적합합니다.
서론
📄 AWS는 상용 이더넷 스위치를 사용해 equal-cost multipath (ECMP) 라우팅으로 high-radix Folded Clos topology를 구축합니다. 이 방식은 TCP의 플로우 별 순서를 유지하는데 유용하지만, 네트워크 사용률이나 흐름 속도(rate)를 고려하지 않습니다. 해시 충돌은 일부 링크에 “핫스폿”을 발생시켜 경로 전반에 걸쳐 균일하지 않은 부하 분산, 패킷 드롭, 처리량 저하, 높은 대기 시간(high tail latency)을 유발합니다. 패킷 지연과 패킷 드롭은 HPC/ML 애플리케이션의 요건인 저 지연을 방해하며, 효율을 떨어뜨립니다. 하나의 이상 값(outlier)이 발생하면 전체 클러스터가 대기 상태로 유지되어 암달의 법칙에 따라 확장성이 제한됩니다.
- ECMP : 하나의 목적지로 패킷 라우팅을 수행하면서 여러 개의 경로를 선택하는 라우팅 기법
- Amdahl’s law : 다중 프로세서를 사용할 때 이론적 속도 향상을 예측하는 법칙
🗣️ 서론에서 제시된 전통적인 TCP의 문제점에 대하여 AWS re:Invent 2022 영상에서 동영상과 함께 굉장히 잘 설명하고 있습니다. 꼭! 해당 영상을 시청하여 TCP 혼잡(Congestion)에 대하여 확인하시기 바랍니다.
Why Not TCP
📄 TCP는 인터넷이 시작된 이래 대부분의 통신에 최적의 프로토콜이지만, 지연 시간에 민감한 처리에는 적합하지 않습니다. 데이터 센터에서 TCP의 경우, 최상의 round-trip latency가 25μs 일 수 있지만, 혼잡 시의 latency outlier는 50ms에서 수초 사이가 될 수 있습니다. 해당 증상의 주원인은 손실된 TCP 패킷의 재전송입니다.
Why Not RoCE
📄 이더넷을 통한 InfiniBand라고도 하는 RoCE(RDMA over Converged Ethernet)는 이론적으로는 AWS 데이터 센터에서 TCP의 대안을 제공할 수 있습니다. 그러나, InfiniBand 전송은 AWS(대규모 네트워크) 확장성 요구사항에 적합하지 않다는 것을 알게 되었습니다.
🗣️ RoCE의 배경지식 이해를 돕기 위해, HUAWEI의 기술 문서를 링크로 첨부합니다. 해당 문서에서 설명하는 RDMA(RemoteDirect Memory Access) 네트워크의 유형과 구조와 TCP/IP의 비교 설명이 해당 문단의 이해에 큰 도움이 되었습니다.
Our Approach
📄 TCP나 다른 전송 프로토콜은 AWS가 필요로 하는 성능 수준을 제공하지 않기에, 하이퍼 스케일 데이터 센터에 최적화된 SRD(네트워크 전송 프로토콜)을 설계하기로 했습니다. SRD는 여러 경로의 로드 밸런싱과 패킷 손실 또는 링크 장애(link failures)로부터 빠른 복구 기능을 제공합니다. SRD는 일반 이더넷 스위치에서 표준 ECMP 기능을 활용하며, 패킷 캡슐화를 조작하여 송신자가 ECMP 경로 선택을 제어합니다. SRD는 특수한 혼잡 제어 알고리즘을 사용하여 패킷 손실 확률을 줄이고 재전송 시간을 최소화하는 등의 성능 향상을 이뤘습니다.
SRD를 AWS Nitro 카드에 구현 함으로서, 물리적 네트워크 레이어와 가깝게 두어 호스트 OS 및 하이퍼바이저에서 주입되는 성능 노이즈를 피할 수 있게 했습니다.
SRD는 EFA PCIe 디바이스로 호스트에 노출되며, Amazon EC2 인스턴스에서 HPC 응용 프로그램 및 ML 분산 훈련을 실행할 수 있게 합니다. EFA는 운영 체제(OS) 바이패스 하드웨어 인터페이스를 사용하여 인스턴스 간 통신 성능을 향상시키는 “유저 스페이스 드라이버”를 제공합니다.
- Nitro Card : 최신 EC2 서버는 메인 시스템 보드와 하나 이상의 Nitro 카드로 구성됩니다. EC2 서비스에서 사용하는 모든 외부 제어 인터페이스를 구현합니다. 또한 소프트웨어 정의 네트워킹, Amazon EBS 스토리지 및 인스턴스 스토리지를 제공하는 데 필요한 것과 같은 모든 I/O 인터페이스를 제공합니다.
- PCIe : 컴퓨터의 여러 부품들이 서로 통신하는 데 사용되는 인터페이스
🗣️ 해당 부분에서는 SRD가 기존 TCP의 제약 사항을 극복하고 어떻게 구성되었는지 설명합니다. 위 설명과 함께 첨부된 Figure 1 그림을 보면, 기 언급된 내용을 확인할 수 있습니다. (SRD는 기존 EFA의 software stack 동일하게, PCIe 디바이스로 호스트에 노출되며 OS를 바이패스(우회) 하는 인터페이스를 제공)
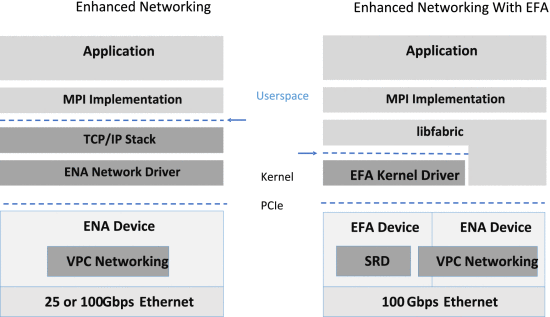
이어서 나오는 디자인 부분에서 더 상세한 설명을 알아보겠습니다.
SCALABLE RELIABLE DATAGRAM DESIGN
Multipath Load Balancing
📄 SRD는 다중 경로를 지원하지 않는 레거시 트래픽과 함께 네트워크를 공유하기 때문에, 각 경로의 round-trip time(RTT) 정보를 수집하여 과부하가 발생한 경로를 피합니다. 또한 SRD는 네트워크 링크 장애 발생 시, 전체 라우팅 업데이트를 기다리지 않고 패킷 재전송 경로를 변경하여 빠르게 복구합니다.
🗣️ 해당 부분에서는 패킷 손실 가능성을 줄이기 위해 트래픽을 사용 가능한 경로에 분산이 필요한 이유와 SRD가 어떻게 여러 경로로 데이터를 분산시키는지에 대해 설명하고 있습니다. AWS re:Invent 2022 영상의 SRD 작동 원리를 설명할 때, 다음과 같이 언급합니다. SRD works by using an ECMP like packet SPRING(Source Packet Routing in Networking) mechanism. 즉, 라우팅 기법으로 ECMP를 채택하여 네트워크의 중간 노드에 의존하지 않고 네트워크의 특정 노드 및 링크 세트를 통해 패킷을 조정하는 SPRING 메커니즘과 같이 동작한다고 합니다. (특정 노드에 의존하지 않으므로, TCP의 해시 충돌로부터 발생한 ‘핫스폿’ 문제 회피)
Out of Order Delivery
📄 여러 경로를 통해 트래픽을 균등하게 분산시키면 대기 시간이 감소하고 패킷 드롭을 방지하는 데 도움이 되지만, large 네트워크에서는 패킷 도착 순서가 잘못될 수 있습니다. 패킷 순서를 복원하는 것은 비용이 많이 드는 작업(평균 대기 시간이 증가하거나 큰 버퍼가 필요)이므로, 순서가 맞지 않더라도 패킷을 호스트에 전달하기로 했습니다. 애플리케이션이 순서를 벗어난 패킷을 처리하는 것은 전송 계층에 메시지 경계가 불투명한 TCP와 같은 바이트 스트리밍 프로토콜에서는 불가능하지만 메시지 기반 시맨틱을 사용하면 쉽습니다. 흐름별 순서 지정 또는 기타 종류의 종속성 추적은 SRD 위의 메시징 계층에서 수행되며, 메시징 계층의 시퀀싱 정보는 패킷과 함께 다른 쪽으로 전송되어 SRD에게는 불투명(opaque) 합니다.
🗣️ 데이터를 연속적인 바이트로 스트림을 보내는 TCP 통신의 개념만 있는 제게는 이 부분을 이해하기 상당히 어려웠습니다. (지금도 제대로 이해하고 있지 못하고 있을 수도 있습니다. 😂) 패킷의 순서가 있는 프로토콜은 수신 측에서 재조립 과정이 있기에 비용(리소스)과 시간이 필요합니다. 하지만 메시지 기반의 SRD는 순서를 맞출 필요가 없으며 이 작업을 메시징 계층에 위임합니다. 때문에 SRD는 메시지 레이어의 작업이 일어나는 방식을 파악하지 않기에 ‘opaque(불투명)’하다고 표현합니다.
- An Introduction to Semantic Routing : 해당 문단의 의미를 파악하는데 가장 도움이 된 Paper입니다. SRD가 채택한 ‘메시지 기반 시맨틱’에 대한 정보가 부족해 어려움을 겪고 있을 때, 이 문서에 나오는 시맨틱 라우팅 개념이 도움이 되었습니다.
Congestion Control
📄 다중 경로 분산은 네트워크 내 중간의 스위치 부하를 줄이지만, incast(다수의 흐름이 스위치의 동일 인터페이스에 집중되어 해당 인터페이스의 버퍼 공간을 고갈시켜 패킷 손실을 초래하는 트래픽 패턴) 혼잡 문제를 줄이는 데 도움이 되지 않습니다. Spraying(경로 분산)은 발신자의 링크 대역폭에 의해 제한되더라도 동일한 발신자의 micro-bursts가 다른 경로에 동시에 도착할 수 있기 때문에 인캐스트 문제를 악화시킬 수 있습니다. 따라서 다중 경로 전송에 대한 혼잡 제어는 모든 경로에서 총 큐잉을 최소화하는 것이 핵심입니다.
SRD 혼잡 제어의 목표는 최소한의 in-flight bytes로 대역폭을 분배하여 큐가 쌓이는 것과 패킷 드롭을 방지하는 것입니다. 이는 BBR과 다소 유사하지만 데이터 센터 다중 경로를 추가로 고려합니다. 이는 연결 당 동적 전송률 제한과 inflight 제한을 기반으로 합니다. 발신자는 전송 속도와 RTT 변경 사항도 고려합니다. 대부분의 경로에서 RTT가 증가하거나 예상 속도가 전송 속도보다 낮아지면 혼잡이 감지됩니다. 이런 방법으로 모든 경로에 영향을 미치는 연결 전체의 혼잡을 감지하며, 개별 경로의 혼잡은 경로 재지정을 통해 독립적으로 처리합니다.
- in-flight bytes : 전송되었지만, 아직 ACK가 되지 않은 패킷
🗣️ 다중 경로 분산은 중간 스위치 부하를 줄이지만, incast 혼잡 문제를 해결하지 못합니다. 대신, 모든 경로에서 총 큐잉을 최소화하여 혼잡 제어를 해야 합니다. SRD 혼잡 제어는 최소한의 in-flight bytes로 대역폭을 분배하고, 큐가 쌓이는 것과 패킷 드롭을 방지하는 것이 목표입니다. 아울러 데이터 센터 다중 경로를 추가로 고려하여 연결 전체의 혼잡을 감지하고, 개별 경로의 혼잡은 경로 재지정을 통해 처리합니다.
USER INTERFACE: EFA
EFA as an Extension of Elastic Network Adapter
📄 Nitro 카드에는 클래식 네트워크 장치를 호스트에 제공하는 동시에 AWS VPC 용 데이터 플레인을 구현하는 ENA PCIe 컨트롤러가 포함되어 있습니다. Enhanced Networking은 하이퍼바이저의 개입 없이 고성능 네트워킹 기능을 제공하며, 기존의 반가상화 네트워크 인터페이스 보다 더 높은 성능을 제공합니다. EFA는 HPC/ML에 적합한 Nitro VPC 카드가 제공하는 추가 옵션 서비스입니다.
- 데이터 플레인 : 서비스의 기본 기능을 제공 예) 실행 중인 EC2 instance 자체, EBS 볼륨 읽기/쓰기, S3 버킷 객체 GET/PUT, Route 53 DNS queries 응답/health checks 수행
🗣️ 해당 부분은 초록에서 언급한 EFA 배경지식을 알고 있는 것으로 충분합니다. Nitro 카드가 제공하던 Enhanced Networking의 방법 중 ENA와 EFA가 있습니다.
EFA SRD Transport Type
📄 모든 EFA 데이터 통신은 queue pairs(QPs)를 통해 이뤄집니다. QP는 전송 큐와 수신 큐를 포함하는 주소 지정이 가능한 엔드포인트 사용자 공간에서 직접 메시지를 비동기적으로 보내고 받는데 사용됩니다. 대규모 클러스터에서 모든 프로세스 간의 모든 연결을 설정하려면 많은 QP가 필요하지만, EFA SRD 전송은 QP의 수를 줄일 수 있습니다. SRD는 InfiniBand reliable datagram(RD) 모델과 유사하지만, 메시지 크기를 제한하고 순서에 맞지 않게 전달하여 RD의 한계를 없앴습니다. 따라서 head-of-line blocking을 생성하지 않고도 애플리케이션 흐름이 서로 간섭하지 않고 다중화될 수 있습니다.
- SRD : 해당 부분에서 참고로 소개된 SRD가 필요한 QP 수를 줄이는 방법을 기재한 문서.
- Head-of-line blocking : 패킷 라인에서 첫 번째 패킷에 의해 큐에 보류될 때 발생하는 성능 제한 현상
🗣️ SRD의 방식과 유사한 InfiniBand에서는 QP는 비용이 많이 드는 리소스뿐만 아니라, 동일한 목적지 QP로 순서대로 전달해야 하는 복잡성이 있습니다. 그러나 SRD는 순서에 맞지 않게 전달하는 특성으로 인해 기존(RD) QP의 복잡성이 줄고 결과적으로 QP의 수를 줄게 합니다.
Out of Order Packet Handling Challenges
📄 EFA SRD QP 의미론(semantics)은 EFA 상위 레이어 처리에 대해 unfamiliar 순서 지정 요구 사항을 도입했고, 이를 “Messaging Layer”라고 합니다. 메시지 계층은 일반적으로 HPC 애플리케이션에서 네트워크 사항(specifics)을 추상화하는 데 사용됩니다. 이 새로운 기능은 신뢰성 레이어가 오프로드되기 때문에 TCP와 같은 전송 구현보다 경량화되어 있습니다.
이상적으로는 메시징 레이어가 수행하는 버퍼 관리 및 흐름 제어는 애플리케이션과 긴밀하게 결합되어야 하는데, 이는 사용자 버퍼 관리 기능이 있는 user-space 네트워킹을 이미 지원하고 HPC와 같은 애플리케이션에 주로 초점을 맞추고 있기 때문에 실현 가능합니다.
메시지 의미론(semantics)을 사용하면 대규모 전송을 위해 메시지 세그먼트가 순서를 벗어난 상태로 도착하면 데이터 복사가 필요할 수 있습니다. 이는 커널 버퍼에서 사용자 버퍼로 복사해야 하는 TCP보다 나쁘지 않습니다. EFA에서는 이 복사본를 RDMA 기능(이 글의 범위를 벗어남)을 사용하여 회피합니다.
🗣️ EFA SRD QP semantics는 “Messaging Layer”라는 새로운 기능을 도입했는데, 신뢰성 레이어가 offload 되어 TCP 보다 경량화되어 있다고 합니다. 상단 Our Approach의 그림에도 나오듯이, SRD는 신뢰성 계층을 하드웨어(EFA device)로 오프로드 시켰습니다. 일반적으로 신뢰성과 관련한 기능은 TCP/IP 스택의 전송 계층에서 수행하지만, EFA에서는 이를 하드웨어에 위임하게 구성했습니다.
SRD PERFORMANCE EVALUATION
📄 동일한 서버 세트에서 AWS 클라우드의 TCP(기본 구성 사용)와 EFA SRD 성능을 비교했습니다. (제약사항 및 실험 범위는 원문 참고)
Incast FCT and Fairness
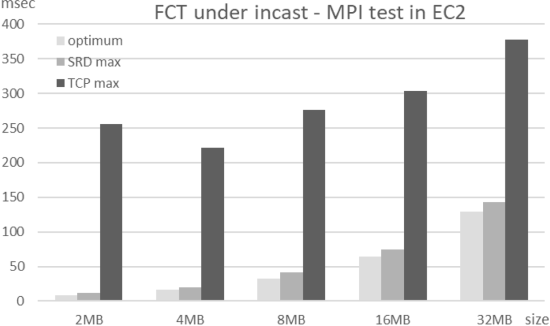
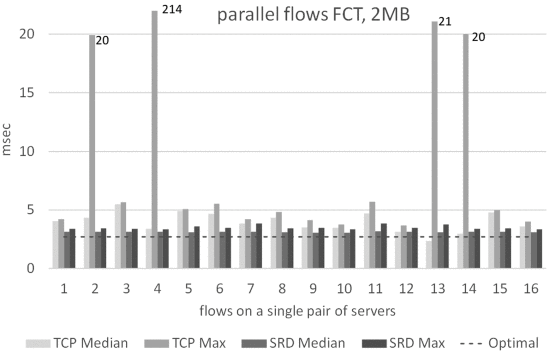
📄 송신자가 barrier를 사용하여 각 전송을 거의 동시에 시작할 때 EFA/SRD 또는 TCP를 통해 MPI bandwidth 벤치마크를 실행했습니다. 아래 그림은 각각의 전송 크기에 대한 이상적인 FCT와 최대 FCT를 나타냅니다. SRD FCT는 매우 낮은 지터로 최적에 가까우며, 최대 시간이 이상보다 3~20배 높을 경우 TCP FCT는 노이즈가 발생합니다.
- barrier : 일종의 동기화 방법, 스레드/프로세스가 다음 단계를 시작하기 전에 모든 프로세스가 준비될 수 있도록 보장
- FCT(Flow Completion Time) : SRD와 TCP에 대한 흐름 완료 시간
다음 그림은 2MB 전송에 대한 FCT의 CDF를 보여줍니다. 최소 재전송 시간제한이 50ms이므로 50ms를 초과하는 TCP tail latency는 재전송을 반영합니다. 50ms 미만의 샘플만 보더라도(즉, 지연이 타임아웃으로 인한 것이 아닌 경우) 많은 수의 샘플이 이상적인 값보다 3배 이상 높습니다.
- Tail Latency : 상위 백분위 응답시간(percentile), 아래 그림에서는 기울기가 완만해지는 우상단 꼬리 모양 부분이 해당
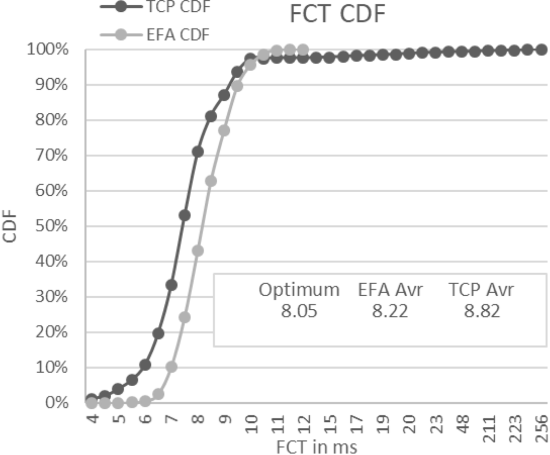
🗣️ 해당 지표에 대한 설명을 이해하기 어려웠지만, EFA가 약 12ms에 100% 도달한 반면 TCP는 3배 이상 되는 약 23 ~ 48ms 부근에서 도달한다는 것으로 이해했습니다.
Flow Throughput Under Persistent Congestion Incast
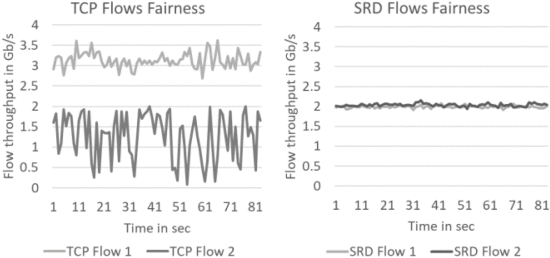
📄 (타임아웃으로 인한 long tail은 무시하더라도) TCP의 높은 FCT 편차(variance)를 이해하기 위해, 인캐스트 하에서 각각의 flow 처리량을 조사(exam) 했습니다. 다음 그림은 데이터를 지속적으로 전송할 때의 각 흐름의 TCP 및 SRD 처리량을 보여입니다. SRD 처리량은 모든 흐름에서 일정하고 이상에 가까운 반면, TCP 처리량은 변동이 심하고 일부 흐름은 예상(2 Gb/s로 설정)보다 평균 처리량이 훨씬 낮습니다.
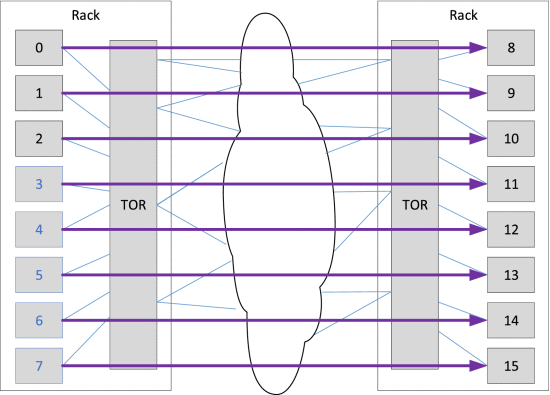
Multipath Load Balancing
📄 동일 랙에 위치한 8대의 서버에서 다른 랙의 8대의 서버로 플로우를 실행한, 상호 연관된 비교적 단순한(less demanding) 사례는 다음 그림과 같습니다. TOR 스위치 업링크는 50%로 활용되며, 다운링크는 하나의 발신자만 수신자에게 보내기 때문에 혼잡하지 않습니다.
- TOR(Top of Rack) : 랙에 설치된 서버들에 대한 트래픽을 수용하기 위해 배치된 스위
이어지는 그림은 8개 수신자 중 한 곳의 모든 흐름에 대한 TCP 및 EFA의 FCT를 보여줍니다. 이상적인 로드 밸런싱을 사용하면 혼잡이 전혀 발생하지 않겠지만, inter-switch 링크에 대한 균일하지 않은 ECMP 밸런싱으로 인해 TCP에서 혼잡과 패킷 드롭이 발생했습니다. TCP 중앙값(Median) 지연 시간은 매우 가변적이며 평균은 예상(점선)보다 50% 높은 반면, 꼬리 지연 시간은 예상보다 1~2배 높습니다. SRD FCT 중앙값은 이상적인 수준보다 15% 높으며, 최대 SRD FCT는 평균 TCP FCT보다 낮습니다.
🗣️ 지금까지 몇 가지의 실험을 통해 SRD가 TCP보다 더 개선되었다는 것을 확인시켜 줍니다. 이 Paper에서 소개하는 실험 외에도 AWS re:Invent 2022 영상의 벤치마크에 대하여 설명하는 영상을 참고해 보세요. (Throughput과 Tail latencies에서 우위를 가졌습니다. 해당 영상에서 TCP는 ENA를 SRD는 ENA Express를 의미합니다.)
CONCLUSION
📄 EFA는 HPC/ML 애플리케이션들을 AWS 퍼블릭 클라우드에서 대규모로 실행할 수 있습니다. SRD를 이용하여 지연 시간이 일관되게 낮아지고 tail latency가 TCP보다 더 낮아집니다. Nitro 카드에서 SRD 다중 경로 로드 밸런싱 및 혼잡 제어를 실행하면 패킷이 끊어질 가능성이 줄어들고, 끊어짐으로부터 더 빠르게 복구할 수 있습니다. 이러한 기능은 네트워크 인터페이스 카드와 호스트 소프트웨어의 여러 계층 간의 기능 분할을 통해 달성됩니다.
🗣️ 결론 부분은 제가 이 논문을 읽으며 느낀 감정을 몇 자 적어보겠습니다. AWS가 기존 데이터 센터가 사용하는 TCP의 한계를 극복하기 위해, 기존에 존재하던 InfiniBand, RD 등의 기술들을 참고하여 SRD를 탄생시킨 부분이 매우 흥미롭습니다. 이 논문에 2020년 11~12월 경에 소개되었는데는, 2년여 뒤 상용화된 제품(ENA Express)까지 내놓게 되는 과정을 확인하니 너무 재미있네요.
Outro
이 글은 올해 작성한 글 중에서도, 글감을 떠올리고 실제 글로 탄생하기까지 가장 오랜 시간이 걸렸습니다. 처음 시도해 보는 논문 리뷰에 대하여 어떤 식으로 글을 작성할지 굉장히 많은 고민을 했습니다. 단순히 한국말로 정보 전달을 하자니 번역기를 옮겨 적은 꼴이고 이미 매우 잘 작성된 AWS Blog 글도 있기에, 어떤 차별점을 주어야 할지 고민했습니다. 그래서 위와 같이 해당 논문을 이해하기 위해 필요한 배경지식들과 제 나름의 이해한 방식을 함께 싣었습니다. 이 글을 통해 SRD에 호기심이 생기신다면, 꼭 한번 원문을 보면 스스로 이해하는 시간을 가져보시기 바랍니다.
소중한 시간을 내어 읽어주셔서 감사합니다! 잘못된 내용은 지적해 주세요! 😃